
supergravity
MYSQL - 문법 정리 : mysql 본문
목차
- SELECT
- WHERE
- AND, OR, NOT
- ORDER BY
- NULL VALUES
- LIMIT
- MIN AND MAX
- COUNT, AVG, SUM
- DISTINCT
- STRING DATE
- LIKE
- IN
- BETWEEN
- ALIASES
- JOIN
- INNER JOIN
- LEFT JOIN
- RIGHT JOIN
- CROSS JOIN
- SELF JOIN
- GROUP BY
- HAVING
- EXISTS
- ANY, ALL
- CASE
- NULL FUNCTIONS
- OPERATORS 모음
count(*) over(partition by team_id)datediff ..>날짜 차이
round(실수, 소숫점)
DENSE_RANK()
limit a offset b
[MS-SQL] 날짜, 시간차이 구하기 (DATEDIFF)
[MS-SQL] 날짜, 시간차이 구하기 (DATEDIFF)
Mir's 운영환경 본체 DeskTop O S Windows7 Ultimate K (Service Pack 1) APP Microsoft SQL Server Management Studio 2012 MS-SQL Micorsoft SQL Server 2008 R2 (10.50.1765.0) MS-SQL 날짜, 시간차이 구하기 (..
mirwebma.tistory.com
https://programmers.co.kr/learn/courses/30/lessons/62284
코딩테스트 연습 - 우유와 요거트가 담긴 장바구니
CART_PRODUCTS 테이블은 장바구니에 담긴 상품 정보를 담은 테이블입니다. CART_PRODUCTS 테이블의 구조는 다음과 같으며, ID, CART_ID, NAME, PRICE는 각각 테이블의 아이디, 장바구니의 아이디, 상품 종류, 가
programmers.co.kr
데이터 분석 팀에서는 우유(Milk)와 요거트(Yogurt)를 동시에 구입한 장바구니가 있는지 알아보려 합니다. 우유와 요거트를 동시에 구입한 장바구니의 아이디를 조회하는 SQL 문을 작성해주세요. 이때 결과는 장바구니의 아이디 순으로 나와야 합니다
IDCART_IDNAMEPRICE
| 1630 | 83 | Cereal | 3980 |
| 1631 | 83 | Multipurpose Supply | 3900 |
| 5491 | 286 | Yogurt | 2980 |
| 5504 | 286 | Milk | 1880 |
| 8435 | 448 | Milk | 1880 |
| 8437 | 448 | Yogurt | 2980 |
| 8438 | 448 | Tea | 11000 |
| 20236 | 1034 | Yogurt | 2980 |
| 20237 | 1034 | Butter | 4890 |
CART_ID
| 286 |
| 448 |
SELECT DISTINCT CART_ID
FROM CART_PRODUCTS
WHERE NAME = '우유' AND
CART_ID IN (SELECT DISTINCT CART_ID
FROM CART_PRODUCTS
WHERE NAME = '요거트')SELECT Statement
SELECT는 데이터 베이스에서 데이터를 가저올 떄 사용됩니다.
SELECT column1, column2, ...
FROM table_name;
SELECT * FROM table_name;WHERE Clause
WHERE는 TABLE에 ROW형태로 저장된 데이터를 필터링 할떄 사용됩니다.
SELECT column1, column2, ...
FROM table_name
WHERE condition;AND, OR and NOT Operators
WHERE와 함께 사용되는 오퍼레이터입니다.
SELECT column1, column2, ...
FROM table_name
WHERE condition1 AND condition2 AND condition3 ...;
SELECT column1, column2, ...
FROM table_name
WHERE condition1 OR condition2 OR condition3 ...;
SELECT column1, column2, ...
FROM table_name
WHERE NOT condition;ORDER BY Keyword
ORDER BY는 SELECT로 가저온 결과를 정렬하는데 사용됩니다.
ASC는 오름차순으로 DESC는 내림차순으로 정렬합니다.
SELECT column1, column2, ...
FROM table_name
ORDER BY column1, column2, ... ASC|DESC;NULL Values
NULL은 VALUE가 없는 데이터를 말합니다.
SELECT column_names
FROM table_name
WHERE column_name IS NULL;
SELECT column_names
FROM table_name
WHERE column_name IS NOT NULL;LIMIT Clause
LIMIT는 데이터 베이스에서 가저오는 데이터수를 제한합니다.
SELECT column_name(s)
FROM table_name
WHERE condition
LIMIT number;MIN() and MAX() Functions
선택된 컬럼에서 가장 작은값과 큰값을 리턴하는 함수입니다.
SELECT MIN(column_name)
FROM table_name
WHERE condition;
SELECT MAX(column_name)
FROM table_name
WHERE condition;COUNT(), AVG() and SUM() Functions
COUNT()는 WHERE에 작성된 CONDITION에 부합하는 ROW의 수를 리턴합니다.
AVG()는 WHERE에 작성된 CONDITION에 부합하는 숫자로 구성된 COLUMN의 평균값을 리턴합니다.
SUM()은 숫자로 구성된 COLUMN의 합을 리턴합니다.
SELECT COUNT(column_name)
FROM table_name
WHERE condition;
SELECT AVG(column_name)
FROM table_name
WHERE condition;
SELECT SUM(column_name)
FROM table_name
WHERE condition;DISTINCT
한 컬럼의 데이터중 중복을 제거할 떄 사용된다.
SELECT DISTINCT column1, column2, ...
FROM table_name;
STRING DATE
아래에 MySQL 함수들은 날짜 데이터에서 일부만을 추출할 수있습니다.
- YEAR : 연도 추출
- MONTH : 월 추출
- DAY : 일 추출 (DAYOFMONTH와 같은 함수)
- HOUR : 시 추출
- MINUTE : 분 추출
- SECOND : 초 추출
DATE_FORMAT(DATE, 형식)을 통해 DATE의 형식을 바꿀 수 있습니다.
형식에는 %Y(4자리 연도), %y(2자리 연도), %m(월), %d(일), %H(24시간), %h(12시간), %i, %s가 있습니다.
SELECT
ANIMAL_ID,
NAME,
DATE_FORMAT(DATETIME, '%Y-%m-%d') AS 날짜
FROM
ANIMAL_INSSTRING( https://yeahvely.tistory.com/89)
DATE(https://jang8584.tistory.com/7)
LIKE Operator
LIKE은 WHERE안에 사용되며, 컬럼 1개에 대해서 특정한 패턴을 찾을떄 사용됩니다.
패턴을 찾을시 2가지의 사인을 사용합니다.
- % : 임이의 여러개의 문자를 나타냅니다.
- _ : 임이의 문자 1개를 의미합니다.
| 기호 | 설명 | 예 |
| % | 0또는 N개의 문자 | bl% => bl, black, blue, and blob |
| _ | 1개의 문자 | h_t => hot, hat, and hit |
SELECT column1, column2, ...
FROM table_name
WHERE columnN LIKE pattern;사용되는 대표적인 예시
| 문법 | 설명 |
| WHERE CustomerName LIKE 'a%' | A로 시작하는 모든 ROW을 찾는다. |
| WHERE CustomerName LIKE '%a' | A로 끝나는 모든 ROW을 찾는다. |
| WHERE CustomerName LIKE '%or%' | OR이 포함된 모든 ROW를 찾는다. |
| WHERE CustomerName LIKE '_r%' | R이 두번째 위치하는 모든 ROW를 찾는다. |
| WHERE CustomerName LIKE 'a_%' | A로 시작하고 최소 크기가 2인 문자열이 있는 모든 ROW를 찾는다. |
| WHERE CustomerName LIKE 'a__%' | A로 시작하고 최소 크기가 3인 문자열이 있는 모든 ROW를 찾는다. |
| WHERE ContactName LIKE 'a%o' | A로 시작하고 O로 끝나는 문자열을 찾는다. |
IN Operator
WHERE와 같이 사용되며 데이터 묶음( (value1, value2, ...))중 포함되는 지 확인할 때 사용합니다.
데이터 묶음은 SELECT로 가져올 수도 있습니다.
SELECT column_name(s)
FROM table_name
WHERE column_name IN (value1, value2, ...);
SELECT column_name(s)
FROM table_name
WHERE column_name IN (SELECT STATEMENT);BETWEEN Operator
BETWEEN은 SELECT에서 주어진 범위만 가져오고자 할때 사용됩니다.
SELECT column_name(s)
FROM table_name
WHERE column_name BETWEEN value1 AND value2;Aliases
테이블의 이름과 컬럼의 이름을 일시적으로 수정할 수 있습니다.
대체적으로는 가공하여 만든 COLUMN의 이름을 붙일때 그리고 다음에 배울 JOIN을 사용할 떄 사용합니다.
SELECT column_name AS alias_name
FROM table_name;
SELECT column_name(s)
FROM table_name AS alias_name;Joins
JOIN은 여러개의 테이블에 대하여 ROW를 합칠 때 사용합니다.
기본적으로는 외래키로 연결이 되어있습니다.
아래 두 테이블이 외래키(CUSTOMERID)로 연결된 예시입니다.
주문현황
| ORDERID | CUSTOMERID | ODERDATE |
| 10308 | 2 | 1996-09-18 |
| 10309 | 37 | 1996-09-19 |
| 10310 | 77 | 1996-09-20 |
사용자 정보
| CUSTOMERID | CUSTOMERNAME | CONTACTNAME | COUNTRY |
| 1 | Alfreds Futterkiste | Maria Anders | Germany |
| 2 | Ana Trujillo Emparedados y helados | Ana Trujillo | Mexico |
| 3 | Antonio Moreno Taquería | Antonio Moreno | Mexico |
각 주문에 대하여 손님의 이름이 무었인지 와 언제 주문했는지 알고 싶다면,
아래와 같이 작성해야 합니다.
SELECT Orders.OrderID, Customers.CustomerName, Orders.OrderDate
FROM Orders
INNER JOIN Customers ON Orders.CustomerID=Customers.CustomerID;INNER JOIN Keyword
INNER JOIN은 두 테이블이 모두 가지고 있는 ROW들만 합하여 가저옵니다.
JOIN과 같습니다.
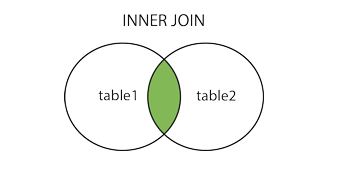
SELECT column_name(s)
FROM table1
INNER JOIN table2
ON table1.column_name = table2.column_name;LEFT JOIN Keyword
LEFT JOIN은 SELECT에서 포함시킨 TABLE1의 모든 데이터를 TABLE2와 합친 결과를 보여줍니다.
만약 TABLE1에는 존재하지만 TABLE2에는 존재하지 않으면 NULL로 저장됩니다.
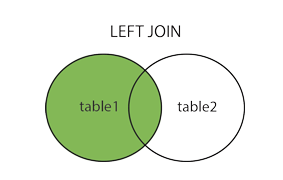
SELECT column_name(s)
FROM table1
LEFT JOIN table2
ON table1.column_name = table2.column_name;RIGHT JOIN Keyword
TABLE2의 모든 ROW에 대해 TABLE1의 결과를 합칩니다.
만약 TABLE1에 존재하지 않는다면 NULL로 저장합니다.
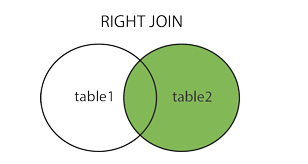
SELECT column_name(s)
FROM table1
RIGHT JOIN table2
ON table1.column_name = table2.column_name;CROSS JOIN Keyword
CROSS JOIN은 모든 ROW를 합칩니다.
존재하지 않는 경우 NULL로 처리합니다.
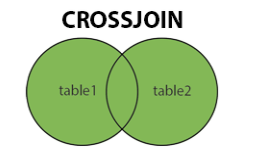
SELECT column_name(s)
FROM table1
CROSS JOIN table2;Self Join
자기 자신을 조인 하는 방법입니다.
SELECT column_name(s)
FROM table1 T1, table1 T2
WHERE condition;GROUP BY Statement
GROUP BY는 같은 값을 가지는 ROW를 묶는 일을 합니다.
대체적으로 GROUP BY는 COUNT(), MAX(), MIN(), SUM(), AVG()함수와 같이 사용하여 묶은 그룹의 결과를 취합합니다.
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
ORDER BY column_name(s);
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country;
SELECT COUNT(CustomerID), Country
FROM Customers
GROUP BY Country
ORDER BY COUNT(CustomerID) DESC;
SELECT Shippers.ShipperName, COUNT(Orders.OrderID) AS NumberOfOrders
FROM Orders
LEFT JOIN Shippers
ON Orders.ShipperID = Shippers.ShipperID
GROUP BY ShipperName;HAVING Clause
HAVING은 GROUP BY이후에 조건문을 사용하고 싶을 때 사용합니다.
SELECT column_name(s)
FROM table_name
WHERE condition
GROUP BY column_name(s)
HAVING condition
ORDER BY column_name(s);EXISTS Operator
EXISTS는 값이 존재하는지 확인합니다.
만약 값이 존재하면 TRUE를 리턴합니다.
SELECT column_name(s)
FROM table_name
WHERE EXISTS
(SELECT column_name FROM table_name WHERE condition);ANY and ALL Operators --- > 다시 정리
ANY는 컬럼의 데이터가 만약 SUBQUERY(위의 예시에서 괄호안의 SELECT를 말한다.)에 존재하면,
TRUE를 리턴합니다.
operator (=, <>, !=, >, >=, <, or <=)
SELECT column_name(s)
FROM table_name
WHERE column_name operator ANY
(SELECT column_name
FROM table_name
WHERE condition);ALL은
SELECT ALL column_name(s)
FROM table_name
WHERE condition;
SELECT column_name(s)
FROM table_name
WHERE column_name operator ALL
(SELECT column_name
FROM table_name
WHERE condition);CASE Statement
케이스에 따라 값을 지정할 수 있습니다.
SELECT OrderID, Quantity,
CASE
WHEN Quantity > 30 THEN 'The quantity is greater than 30'
WHEN Quantity = 30 THEN 'The quantity is 30'
ELSE 'The quantity is under 30'
END AS QuantityText
FROM OrderDetails;
OrderID Quantity QuantityText
10248 12 The quantity is under 30
10248 10 The quantity is under 30
10248 5 The quantity is under 30
10249 9 The quantity is under 30
10249 40 The quantity is greater than 30
10250 10 The quantity is under 30
10250 35 The quantity is greater than 30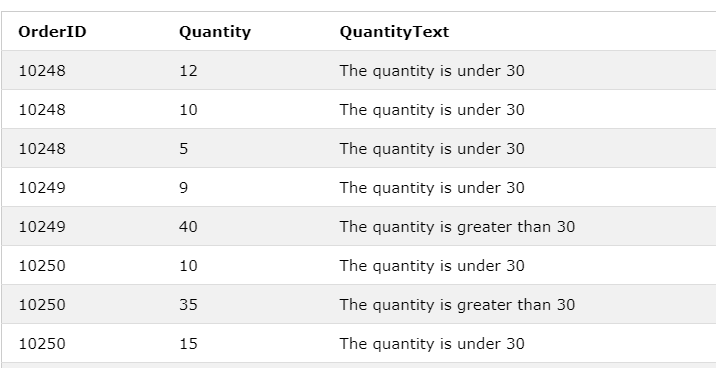
SELECT CustomerName, City, Country
FROM Customers
ORDER BY
(CASE
WHEN City IS NULL THEN Country
ELSE City
END);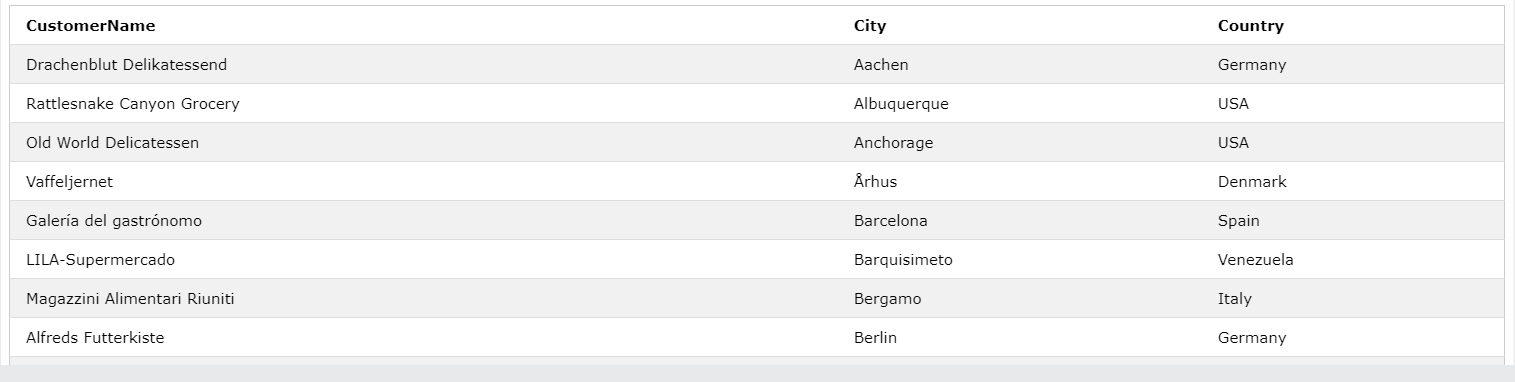
IFNULL() and COALESCE()
IFNULL(COL, 다른 값)은 COL을 받고 만약에 NULL이면 '다른 값'으로 변경합니다.
SELECT ProductName, IFNULL(UnitsOnOrder, '눌이야')
FROM Products;COALESCE()는 NULL이 아닌 처음 값을 리턴합니다.
SELECT ProductName,COALESCE(UnitsOnOrder, 'NULL이야')
FROM Products;위의 두 문법은 같은 결과를 출력합니다.
Operators 모음
| OPERATOR | 설명 |
| + | Add |
| - | Subtract |
| * | Multiply |
| / | Divide |
| % | Modulo |
| OPERATOR | 설명 |
| & | Bitwise AND |
| | | Bitwise OR |
| ^ | Bitwise exclusive OR |
| OPERATOR | 설명 |
| = | Equal to |
| > | Greater than |
| < | Less than |
| >= | Greater than or equal to |
| <= | Less than or equal to |
| <> | Not equal to |
| OPERATOR | 설명 |
| += | Add equals |
| -= | Subtract equals |
| *= | Multiply equals |
| /= | Divide equals |
| %= | Modulo equals |
| &= | Bitwise AND equals |
| ^-= | Bitwise exclusive equals |
| |*= | Bitwise OR equals |
| OPERATOR | 설명 |
| ALL | TRUE if all of the subquery values meet the condition |
| AND | TRUE if all the conditions separated by AND is TRUE |
| ANY | TRUE if any of the subquery values meet the condition |
| BETWEEN | TRUE if the operand is within the range of comparisons |
| EXISTS | TRUE if the subquery returns one or more records |
| IN | TRUE if the operand is equal to one of a list of expressions |
| LIKE | TRUE if the operand matches a pattern |
| NOT | Displays a record if the condition(s) is NOT TRUE |
| OR | TRUE if any of the conditions separated by OR is TRUE |
| SOME | TRUE if any of the subquery values meet the condition |
'콘텐츠 > mysql - 문법 기초' 카테고리의 다른 글
| mysql - GROUP_CONCAT (0) | 2021.11.27 |
|---|---|
| mysql - rank, dense_rank, row_number (0) | 2021.11.26 |
| mysql - 서브쿼리(subquery) 응용 (0) | 2021.11.22 |
