
supergravity
파이썬 - 스트링을 메모리에 어떻게 저장할까? 본문
그래서 파이썬에서 어케 메모리에 저장하는데?
파이썬 3 버전 이후로 str타입은 unicode를 이용하여 메모리에 저장을 합니다.
여기서 unicide란 사람의 언어를 컴퓨터의 언어인 2진법에 1대 1로 대응시킨 함수 또는 표를 말합니다.
unicode에서 문자들은 1문 자당 4바이트 까지 사용됩니다.
만약 이를 그대로 사용하게 되면 많은 양의 문자를 사용할 때 메모리 관점에서 낭비될 수 있습니다.
이러한 메모리 소비를 줄이기 위해 성능을 향상하기 위해서
파이썬은 3가지 종류의 내부 표현방식을 사용하고 있습니다.
* latin-1 encoding : 1바이트당 1개의 문자
* ucs-2 encoding : 2바이트당 1개의 문자
* ucs-4 encoding : 4바이트당 1개의 문자
파이썬을 사용하다 보면 모든 스트링들이 같은 행동을 하는 것처럼 보입니다.
사실 대부분의 경우 차이점을 알아차릴 수도 없을 정도로 미미합니다.
하지만 많은 양의 문자를 다룰 때 엄청난 차이가 있습니다.

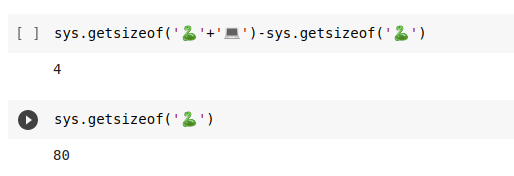
보다시피 스트링에 어떠한 문자를 넣냐에 따라서 크리가 달리 저장됩니다.
영어에! 는 크기가 1바이트인 반면 한국어의! 는 크기가 2입니다!
또한 모든 문자열에는 49에서 80바이트의 추가적인 메모리가 필요합니다.
여기에는 파이썬이 스트링을 메모리에 저장 시 필요한 다른 정보들을 저장합니다.
따라서 아무것도 없는 스트링을 저장하게 되면
49바이트의 메모리를 소모합니다.
그러면 진짜 그런지 확인해 봅시다!

실제 문자가 1인 경우 50 바이트의 크기이지만
아무것도 없는 경우 53입니다.
무슨 일일까요?
정확히는 모르겠지만..
아무것도 없는 경우 none과 같이 크기가 4이고 없다는 의미를 가지는 영어로 된 문자가 기본적으로 저장되는 것 같습니다.
그러면 문자가 1개 일떄 50 문자가 4개 일 때 53이니 진짜 문자 엘 세팅에 필요한 메모리는 49인 것을 알 수 있습니다.
# 한국어를 변환하는데 UTF-8이란 것을 쓴 거 같은데 파이썬은 안 쓰는 건가??
결론부터 말하면. 사용하지 않습니다.
UTF-8은 전 세계에서 가장 많이 알려진 사람의 문자를 컴퓨터의 언어인 0과 1로 변환시켜주는 방식입니다.
그러면 도대체 왜 파이썬은 UTF-8을 사용하지 않아서
우리를 힘들게 하는 것일까요?
UTF-8의 경우 문자들에 따라 1-4바이트의 크기를 가집니다. 예를 들어
문자열! 더더더 haha의 경우 1+2+2+2+1+1+1+1 = 11의 크기를 가집니다.
대충 보면 효율적으로 보이지만 여기에는 가장 큰 문제가 있습니다.
> 파이썬에서 문자열의 각 문자에 시간 복잡도가 상수 O(1)로 접근할 방법이 없다는 것! 파이썬이 UFT-8을 사용한다면 원하는 문자가 나올 때까지 문자열을 처음 주터 끝까지 찾아 헤맬 것입니다 ㅠㅠ
결국 utf-8을 이용하면 공간 복잡도는 잡을 수 있어도 시간 복잡도를 잡을 수 없어 파이썬에서는 사용하고 있지 않고 있습니다!
파이썬은 문자열에서 문자의 위치를 인덱스와 엔코딩 길이(한글 2 영어 1)를 곱해 한번에 찾아냅니다!
# 파이썬 String interning
파이썬에서는 string interning이라는 방식을 사용하고 있습니다.
string intering이란 여러 개의 문자열 값에 대해서 한 가지의 값만 가지는 방법을 말합니다.
또한 대표되는 값은 메모리에 저장이 되며 이 값은 변환될 필요가 없어 변화되는 방법을 제공하지 않으며 이를 immutable이라고 합니다.
대표되는 값은 distinct memory라는 곳에 독립 적으로 보관됩니다.
그러면 예제를 통해 알아봅시다.


한글이든 영어든 섞어 쓰든 간에 결국 distinct memory에 저장된 하나의 값만 사용을 합니다.
그러나 distinct memory에서 가져와 string 값이 저장된 메모리에 저장될 때는 언어에 따른 엔코딩 방법을 사용합니다
(영어일 때 1칸 = 1바이트 한글일 때 2칸 = 2바이트)
또한 파이썬에서는 한문자만 독립적으로 저장하는 것이 아니라 20 문자 이하의 스트링 들은 한꺼번에 distinct 메모리에 저장됩니다.
(이거 좀 어렵습니다.. 효율적으로 작동해야 해서 복잡한 메커니즘이 있습니다. 그래서 묻어 둡시다.)
파이썬 스트링이 distinct memory에서 데이터를 가져와 사용하는 특성은 스트링의 immutable특성을 가지게 만들었고 (String interning 체계를 따른 것입니다.)
ram의 특성인 상수 시간으로 데이터에 접근하는 방법을 구현하기 위해여 한 문자열 안의 문자의 데이터 길이를 같게 해서 인덱스와 한문자의 길이만 알면 접근 가능하도록 구현했습니다.
결과 적으로 파이썬은 문자열이 생성된다 싶으면 distinct메모리에 있나 확인을 먼저 하고 있으면 그 풀에서 검색하여 가져옵니다. 없는 경우 distinct 메모리 풀에 추가를 합니다.
실제 여기서 다루지 않은 내용이 졸라게 많습니다.
특히 문자 20개 이하일 때 한꺼번에 distinct 메모리에 저장되는데 어떻게 효율적으로 저장이 되게 해 놓았는지 구체적으로 설명을 하지 않았습니다.
거기에 대해서 궁금하시면 아래의 링크를 참고하시면 좋을 것 같습니다.
https://github.com/python/cpython/blob/main/Objects/unicodeobject.c
GitHub - python/cpython: The Python programming language
The Python programming language. Contribute to python/cpython development by creating an account on GitHub.
github.com
'콘텐츠 > 파이썬 -구조' 카테고리의 다른 글
| 파이썬 - __main__ (0) | 2021.09.08 |
|---|---|
| 파이썬 - namespaces, scopes (0) | 2021.09.06 |
| cython , cpython, python ? (0) | 2021.09.04 |
| 파이썬 - 메모리 관리와 좋은 습관 (9) | 2021.08.31 |

